Requirements#
Documentation is applicable for a version 10.4.0-1209.942 or later.
Pre-requisites#
Below are the prerequisites for the automation to run. You need to:
- Install AWS CLI locally and Configure AWS cli
- Install EKSCTL locally
- Install HELM locally
- Note:
- AWS access key and secret key should be configured either via aws configure or using gradle project properties. '-PaccessKey= -PsecretKey='
How the full flow works#
- Installing a docker based Deploy instance, because we will use Deploy to create necessary resources in kubernetes and to deploy an operator.
- Checking out Deploy operator and modifying the configuration based on the user input
- Installing XL CLI to apply YAML files
- Verifying that deployment was successful and all required resources were created in kubernetes. If something went wrong, you'll be notified about it in logs.
You can also check this operator AWS EKS documentation for more information.
All of this is automated and can be triggered by ./gradlew clean :core:startIntegrationServer --stacktrace with the configuration that is similar
to the following example.
When you would like to stop your cluster you can run ./gradlew :core:shutdownIntegrationServer --stacktrace.
It will undeploy all CIs, remove all deployed resources on kubernetes and clean all created PVC.
Example#
An example for a complete configuration:
deployIntegrationServer { cli { overlays = [ ext: [ fileTree(dir: "$rootDir/config/cli", includes: ["**/*.py"]) ], lib: [ "com.xebialabs.xl-platform.test-utils:py-modules:${testUtilsVersion}@jar" ] ] } cluster { enable = true profile = 'operator' publicPort = 10001 } clusterProfiles { operator { activeProviderName = "aws-eks" awsEks { name = 'aws-eks-test-cluster' region = 'us-east-1' } } } servers { server01 { dockerImage = "xebialabsunsupported/xl-deploy" pingRetrySleepTime = 10 pingTotalTries = 120 version = "${xlDeployTrialVersion}" overlays = [ conf: [ fileTree(dir: "$rootDir/config/conf", includes: ["*.*"]) ], ] } server02 { } } workers { worker01 { dockerImage = "xebialabsunsupported/deploy-task-engine" } worker02 { } }}The cluster will be created with amount of servers and workers specified in the configuration. For this case,
it will create 2 masters and 2 workers. The final URL to connect to UI is:
http://deploy.digitalai-testing.com/xl-deploy/#/explorer.
In case if you want to update the operator and use your own, you can change operatorImage.
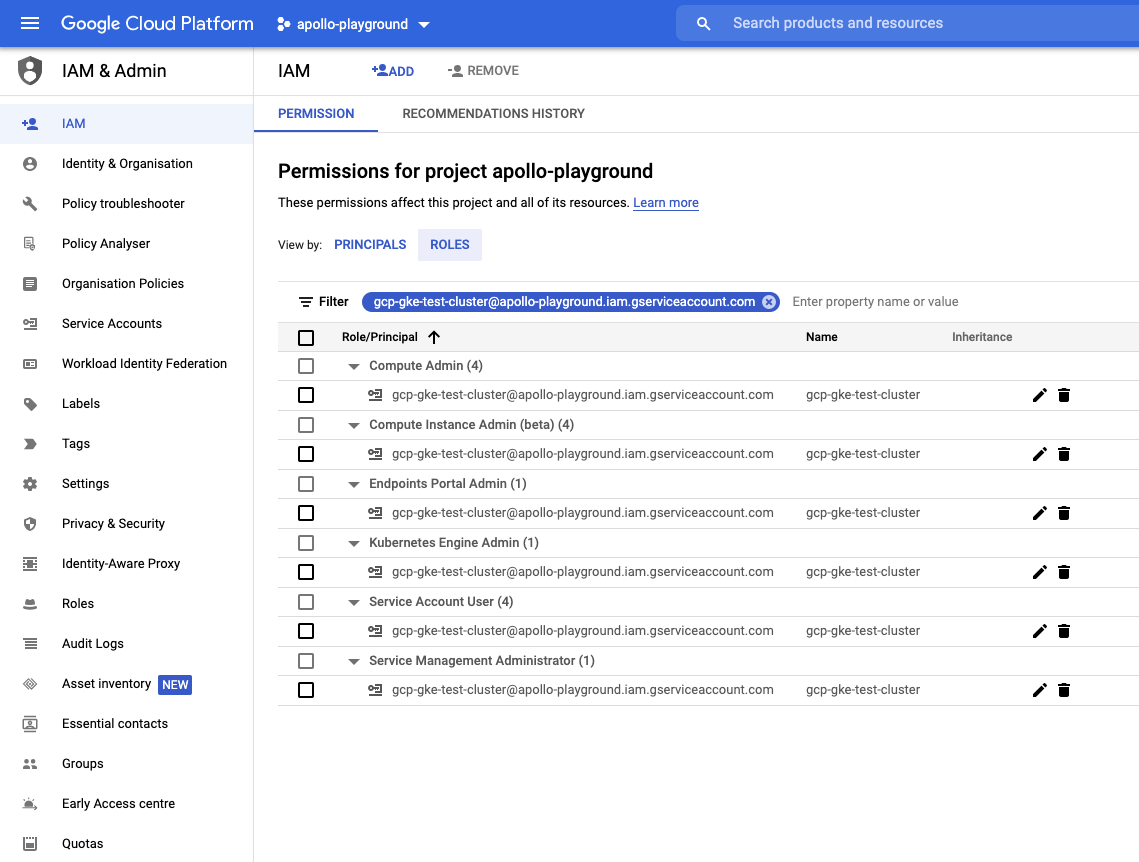 More details about IAM policies for GKE are here:
More details about IAM policies for GKE are here: